{kind=link}
斯坦福意外用AI生成超强CUDA内核,性能比人类专家优化得还要好!翻倍碾压原生PyTorch,华人主创
好家伙,AI 意外生成的内核(kernel),性能比人类专家专门优化过的还要好!
斯坦福最近披露了一组新发现,结果真的太亮眼了。
由 AI 优化的内核,在常见深度学习操作上,翻倍超越原生 PyTorch,性能至多可以提升近 400% ——
矩阵乘法(Matmul,FP32):性能达到 PyTorch torch.matmul 的 101.3%。
二维卷积(Conv2D):性能达到 torch.nn.Conv2D 的 179.9%。
Softmax:性能达到 torch.softmax 的 111.8%。
层归一化(LayerNorm):性能达到 torch.nn.LayerNorm 的 484.4%。
Conv2D+ReLU+MaxPool 组合操作:性能达到 PyTorch 参考实现的 290.1%,以及 torch.compile ( ) 参考实现的 189.0%。
(在 NVIDIA L40S GPU 上进行基准测试,性能百分比定义为参考时间除以生成的 kernel_size 时间)

更惊人的是,这一切都是意外实现的。
研究团队本来的目标是生成合成数据以训练内核生成模型。
结果发现,仅在测试阶段生成的合成数据本身,竟然可以生成性能非常优秀的内核。
围观网友:没想到 AI 也要取代内核工程师了。
还有人发现,除了性能大幅提升外,研究团队采用的方法也非常有趣:
他们没有简单的在操作上逐步优化(类似于爬坡算法),而是在每次迭代之间加入了一个语言推理的步骤,通过这种方式鼓励搜索过程更加多样化。
也就是说,他们是让系统在每次改进时通过类似 " 思考 " 的方式产生更多想法,从而找到更好的解决方案。

具体如何实现,一起来看。
改代码前先生成自然语言优化思想
按照斯坦福团队博客的描述,这种内核生成的思路非常简单——给定 torch 代码,然后告诉都能写编写自定义内核来替换 torch 算子。
这些内核是用纯 CUDA-C 编写,无需使用 CUTLASS 和 Triton 等库和 DSL(Domain-Specific Language,领域专用语言)。
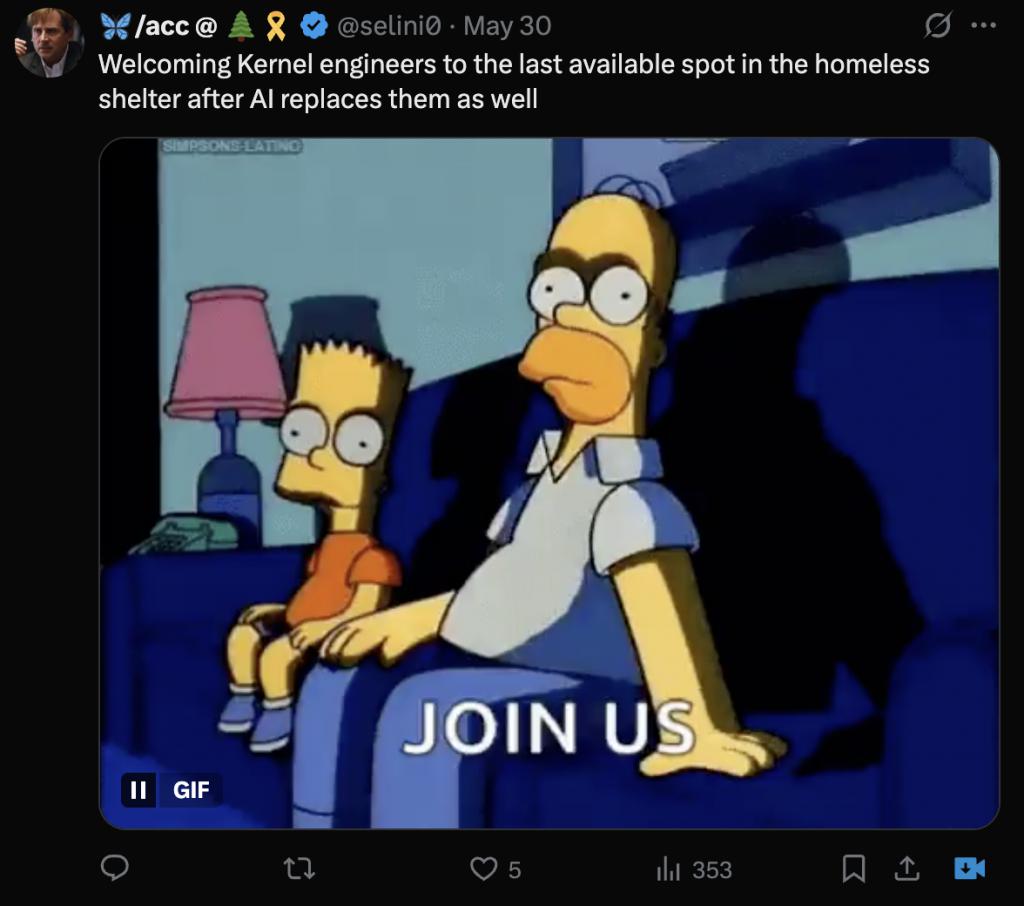
不同于传统方法的是,模型并不是一上来就直接改代码,而是先用自然语言生成优化思想,然后再将这些思想转化为新的代码变体。
团队这样做的理由是," 按顺序修改 " 式的优化思路缺乏多样性,导致陷入局部极小值,重复访问同一类转换或无休止地优化没有前景的轨迹。
为了进一步增强思路多样性,斯坦福团队还使用了多分支的探索模式。
具体来说,他们的方法并非每一步都只优化一个候选方案,而是将每个想法分散开来,使其衍生出多个实现,并使用性能最高的内核作为下一轮的种子。
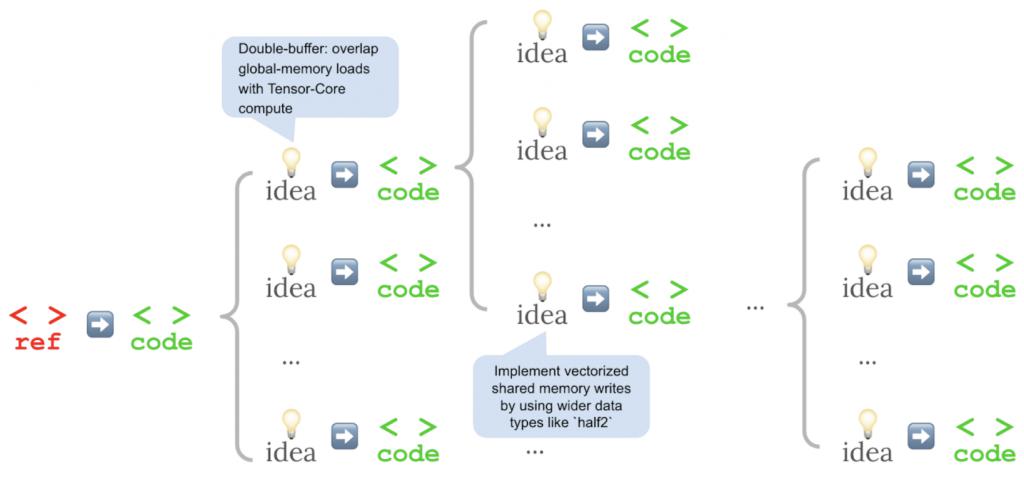
团队使用 OpenAI o3 和 Gemini 2.5 Pro 挑战 KernelBench 1 级中的 10 个问题,运行多轮后,最佳内核开始出现。
其中大多数最佳结果出现在后续轮次(总共 5 轮),并且主要是第 4 轮或第 5 轮。
KernelBench 是斯坦福团队自己提出的一套 AI 生成内核测试基准,基准中的任务分为 3 个级别,其中 1 级是指单一原始操作(Single primitive operation),包括 AI 的基础构建块(例如卷积、矩阵 - 向量与矩阵 - 矩阵乘法、损失函数、激活函数以及层归一化)。
这一发现再加上之前 DeepMind 的 AplhaEvolve,以及 o3 发现 Linux 的 0day 漏洞等一系列事件,让网友们认为 Gemini 2.5Pro 和 o3 的能力水平已经达到了新的层级。

回到斯坦福的项目,在生成过程当中,可以看到模型的生成思路开始显现出与人类的经验相似之处——
内存访问优化: 提高不同内存层次结构(全局内存、共享内存、寄存器)之间数据移动的效率,并确保以最大化带宽和最小化冲突的方式访问数据;
异步操作和延迟隐藏: 通过将慢速操作(如全局内存访问)与计算或其他内存传输重叠," 隐藏 " 慢速操作的延迟;
数据类型和精度优化: 尽可能使用低精度数据类型(如 FP16 或 BF16)以减少内存带宽要求、提高缓存效率;
计算和指令优化:提高算术计算本身的效率,减少指令数量,或利用专门的硬件指令;
并行性和占用率增强:最大化流多处理器(SM)上的活动线程数量,以更好地隐藏延迟并提高整体吞吐量;
控制流和循环优化:减少与循环、分支和索引计算相关的开销。
并且斯坦福团队还展示了一组具体的优化轨迹,从中可以看出,并不是每一步优化都一定能让速度更快,但经过多个步骤的组合,内核的速度能够得到大幅提升,并最终超越 PyTorch。

在具体实现上,有人询问 AI 生成 CUDA 内核时的优化建议,是否可以被转化为对应代码实现、还是说只是触发了随机探索?
作者回应说,尽管还没有进行更严谨的系统验证,但是手动检查的案例中,生成的 CUDA 视线与提出的优化建议是大致匹配的。
即 AI 并不是在完全随机做优化,而是确实在尝试实现它自己提出的策略。
华人主创团队意外发现
这项研究共有三位作者:Anne Ouyang、Azalia Mirhoseini 和 Percy Liang。
Ouyang 目前是斯坦福大学扩展智能实验室的博士生,她本硕毕业于麻省理工,曾在英伟达 cuDNN 团队工作。

Percy Liang 是斯坦福大学计算机科学副教授兼统计学助理教授,目前担任斯坦福基础模型研究中心主任。
曾和李飞飞一起发布、推进了多项研究工作。

Azalia Mirhoseini 是斯坦福大学计算机科学助理教授、斯坦福扩展实验室创始人。她曾在 DeepMind、Google Brain 以及 Anthropic 工作过。
她此前参与的研究包括 MoE、芯片设计算法 AlphaChip 等。

本次研究,本来是希望生成数据来训练内核生成模型。
但是在过程中却出现了意想不到的结果,仅在测试阶段生成的合成数据本身,竟然可以生成性能非常优秀的内核。
因为这些内核利用了此前被认为很难实现的高级优化和硬件特性,所以团队决定以博客形式分享此次成果。
不过具体是如何生成数据的,研究团队暂时不对外发布,只是提到了这种设计理念也很简单。
最关键的还是,它已经展示出了巨大潜力。
此外,研究团队也认为此次发现也与最近的一些趋势相呼应——大规模再训练已不是必需。
有时,聪明的搜索和分支策略,可以解锁科学创新并解决复杂问题,通过 verifier 进行广泛搜索还能有更多收获。
将强大推理能力与同时探索多个假设结合起来,能带来更好结果。就像 AlphaEvolve、AlphaEvolution、 Gemini 2.5 Pro 深度思考一样。
最后,团队表示这项研究还有很多可优化的空间。比如他们手头上就还在优化两个维度:
FP16 Matmul:52% performance of torch.matmul
FP16 Flash Attention::9% performance of torch.nn.functional.scaled_dot_product_attention
与 FP16 或 BF16 相比,FP32 在新推出硬件上的优化程度通常比较低,这也是为何使用 FP32 内核比 PyTorch 更容易实现性能提升。
他们表示,虽然现在还有不少限制,但是对于未来前景还是很乐观的。
毕竟最开始,他们连能正常运行的内核都生成不了,但是通过不断优化搜索方法,已经能让 flash attention 的性能提升到了一个不错的水平。
值得一提的是,搜索使用的资源也很少,大概只用了 300 万 token 输入和 400 万 token 输出。
One More Thing
实际上,不只是一个团队在尝试开发内核大模型。
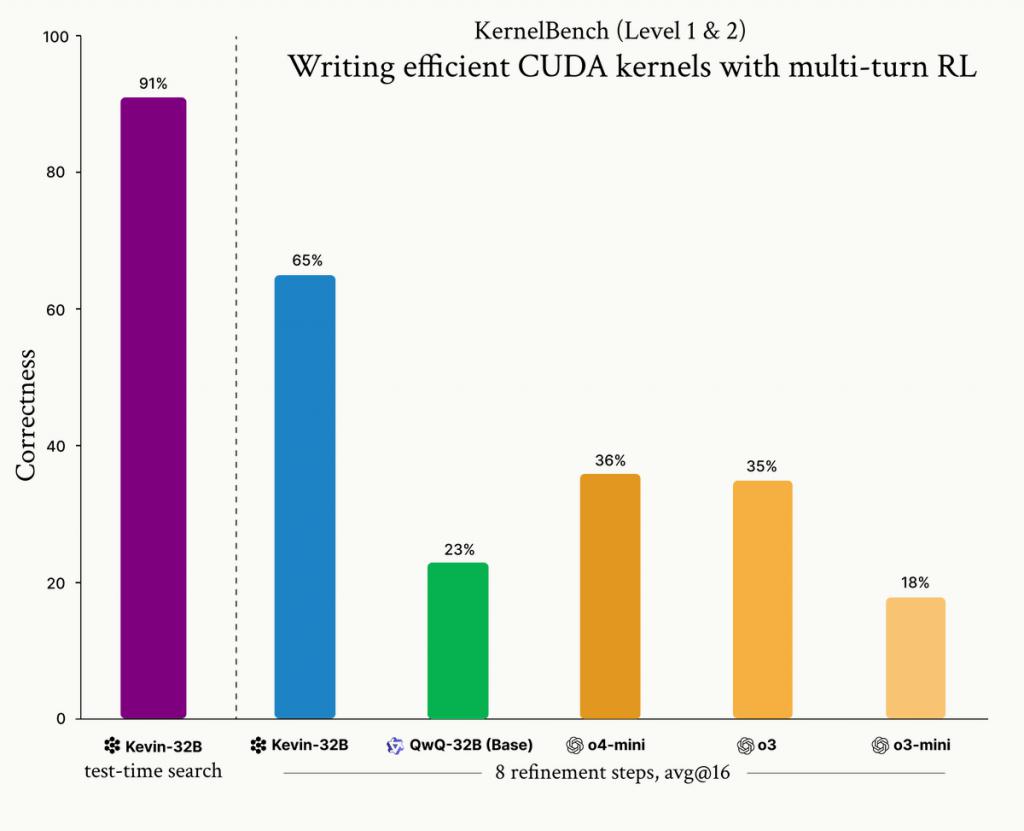
就在 5 月,开发了 Devin 的 Cognition 开源了首个通过强化学习即可编写 CUDA 内核的大模型 Kevin-32B。
它基于 QwQ-32B 在 KernelBench 数据集上使用 GRPO,实现了多轮强化学习,性能优于 o3、o4-mini。
参考链接:
[ 1 ] https://crfm.stanford.edu/2025/05/28/fast-kernels.html
[ 2 ] https://x.com/anneouyang/status/1928124885567467768
[ 3 ] https://x.com/cognition_labs/status/1919835720493236295
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!