{kind=link}
一句话生成带对话影片、Gemini全面接管搜索、全家桶秒变通用Agent ,以及Google Glass is so back!
谁也没想到,Google I/O 现场的最高潮来自 " 复活 " 的 Google Glass 有些翻车了的实时 demo。

2025 年 5 月 20 日,Google 的年度开发者大会 Google I/O 在加州山景城举办。与去年在举办之前一天被 OpenAI" 狙击 " 不同,今年的 Google I/O,剑拔弩张的氛围让位给了派对的氛围,在 ChatGPT 带来的狼狈之后,Google 已经回到了自己的节奏。
是的,它回到了饱和式发布的节奏。当天 Google 一口气发布了至少十多个 AI 相关的更新,而其中大多数和 Gemini 有关。
简单说,Google 主要做了四件事:展示 Gemini 在多模态上的遥遥领先;给 Gemini AI 助手做全方位的更新;让 Gemini 彻底接管搜索,并让全家桶变成通用 Agent;以及令人兴奋的 AI+AR 眼镜。
这些发布个个重要,但因为 AI 模型层面本身的进展在过去几年已经吊足了大家胃口,以及 Google 在此次大会之前已经发布了 Gemini 最新的大迭代,现场似乎显得平静。

直到 Google Glass 的 " 复活 "。它通过 live demo 彻底点燃了现场。
Google Glass is so back
当天的 Google I/O 一共只有三四个 Live demo,而最后出场的 Android XR 眼镜,是最让人兴奋的一个。
在喧嚣的 I/O 后台,演示者 Nishta 戴上了这款看起来与普通眼镜无异的 Android XR 眼镜,为观众带来第一视角的体验。
她先是对着镜子喝了一口咖啡,通过语音指令发送短信、设置手机静音,询问眼镜里内置的 Gemini,她看到的墙壁上的乐队与这个剧场的关系,而这一切的答案和互动,都通过眼镜上实时悬浮显示,呈现在她眼前。
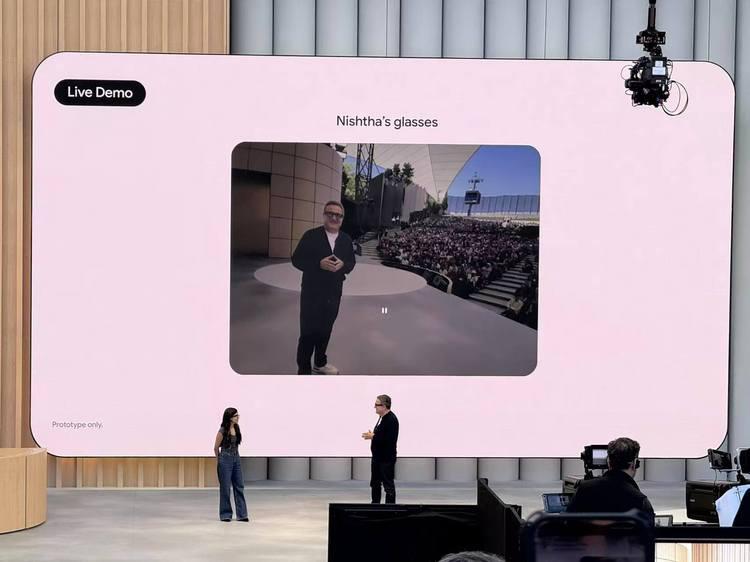
而且,像极了故意对当年 Google Glass 太超前而被公众质疑的 call back,当展示者戴着眼镜从后台出发,遇到的第一个人对她说:" 你眼镜在闪烁,我是在直播里么?" 然后很开心的参与了互动,而不是说 " 摘掉你的 Google Glass"。
是的,这一切都是为了展示眼镜里 Gemini 视觉记忆能力:当来到主舞台后,Nishta 随口问起之前喝过的咖啡,Gemini 竟然凭借杯子上模糊的印记,准确报出了咖啡店的名字 "Blooms Giving"。接着咖啡店的图片、3D 步行导航地图、给朋友发送的咖啡邀约,都通过很有 Google 特色的悬浮交互完成。
(插入视频)
最后他们甚至做了一个实时的 " 有风险出错 " 的演示—— Nishta 和台上的 Shahram 分别用印地语和波斯语进行对话,而两人镜片上实时滚动出英文的字幕。而在展示中,这部分的确卡顿了,但即便最终有些翻车,现场却依然一片掌声和欢呼。因为这基本就是接下来所有人期待的 AI 发展方向。
当 Gemini 的一切能力都可以跟现实世界,物理环境交互,并且通过视觉和语音的端到端的方式可以拥有记忆、执行和行动能力后,将解锁太多可能。
据 Google 介绍,Android XR 智能眼镜将搭载 Gemini Live AI 助手,通过镜头、麦克风和可选的内置显示器,实现语音互动、拍照、地图导航、实时翻译等功能,不用掏出手机就能完成任务。设备将与手机联动,支持全天佩戴,外观方面也将与 Gentle Monster、Warby Parker 等时尚品牌合作打造。目前没有公布价格和上市时间,但谷歌确认今年会开放平台,供开发者为 XR 生态构建应用。
值得注意的是,谷歌在 XR 硬件上似乎也越来越依赖三星。谷歌 XR 副总裁 Shahram Izadi 在官方博客中提到,他们正与三星深化合作,不仅做头显,还将一起推进智能眼镜。而在 I/O 大会上,谷歌还宣布首款搭载 Android XR 的智能眼镜将由 Xreal 打造,项目代号为 Project Aura。
Gemini 接管 Google 的一切
在眼镜点燃现场之前,Google I/O 更像是 Google 一个密集的 AI 军火展示。
今年坐在 Google IO 的圆形剧场里,你能非常直观感受到一年时间对于今天的 AI 来说,能发生多少事情。
当 Google CEO Sundar Pichai 站上当天的舞台,Google 面前已经没有了 OpenAI 的偷袭搅局,Llama 被 DeepSeek 彻底打乱阵脚,微软的 Build 仍让人担心它和 OpenAI 的关系,而 Gemini 自己的多模态能力则在一年的不停突破后站稳了领先,天天被念叨的搜索业务没有被 Perplexity 们冲垮,广告基本盘更是在最近财报里仍在超预期增长,归因也是 " 因为 AI"。
甚至人们都快忘了,在 Google I/O 上接过 Pichai 话筒的,已经是 " 诺贝尔化学奖得主 "Demis Hassabis。

在当天的 Google I/O 上,Pichai 的开场 Keynote 回到了久违的 Google 味儿,一切是 Google 自己的节奏而不是慌慌张张的应对。
" 通常,在 I/O 大会召开前的几周,我们不会透露太多信息,因为总会把最重磅的模型留到大会上发布。"Pichai 说。" 然而在 Gemini 时代不同了 。现在,我们很可能在 IO 前就发布了最智能的模型,或者提前一周公布像 AlphaEvolve 这样的突破 。我们的目标是尽快将最出色的模型和产品交付到大家手中 。我们速度前所未有的快 。"
在 Pichai 的开场分享里,是一连串体现速度的数字。
Gemini 应用月活跃用户超过 4 亿;Gemini 应用中 2.5 Pro 使用量增长了 45%;产品和 API 每月处理的 token 数从去年同期的 9.7 万亿增长到超过 480 万亿,增长了 50 倍;超过 700 万开发者正在利用 Gemini 进行构建,是去年同期的 5 倍;Vertex AI 上 Gemini 使用量增长了 40 倍。
而模型上,Pichai 甚至直接喊出 Google 已经遥遥领先。
自第一代 Gemini Pro 模型发布以来,它的 Elo 分数提升了 300 多分。(衡量大模型能力的 ELO 是一种通过模型之间两两匿名对比(类似下棋)的结果,来计算和更新各个模型相对实力排名的方法);第七代 TPU Ironwood 比上一代性能提升了 10 倍。每个 pod 提供 42.5 exaflops 的计算能力。
AI 的渗透也带来 Google 产品的增长。
Search 中的 AI 概览已覆盖超过 15 亿用户。 目前已在 200 个国家和地区推出;在美国和印度等最大市场,推动显示它们的查询类型增长超过 10%;AI mode 早期测试者提出的查询长度是传统搜索的 2 到 3 倍。
去年,Pichai 就已经开始形容 Google 的员工已经是 "geminier",而今年的 I/O 当天正是 Gemini(双子座)季节的第一天,他开玩笑形容在 Google 内部来说,每天都是 Gemini 季节。
甚至在他的演讲保留环节 " 统计 AI 出现次数 " 的环节,Gemini 正式超过了 AI 成为他说的最多的单词。

对 Google 来说,走出 ChatGPT 猛攻之下的狼狈,一切都靠 Gemini 的反杀。
而 Demis Hassabis 显然就是让这一切发生的那个人,当他出场,后面的 AI 生成的图像甚至都是一只山羊—— GOAT(greatest of all time)。

当天 Hassabis 的分享部分,其实更像是一场诺贝尔得主回家见面会,他回顾了他从最初痴迷用 AI 做乒乓球游戏,到 Google 的 Transformer、AlphaGo,再到 Gemini 的历程。言外之意,向全 AI 界喊话,Google 永远是你大爷。
而这位新晋诺奖得主也更加直白了,他表示他的最终目标是做出一个世界模型,而 Gemini 现在无比接近这个愿景。
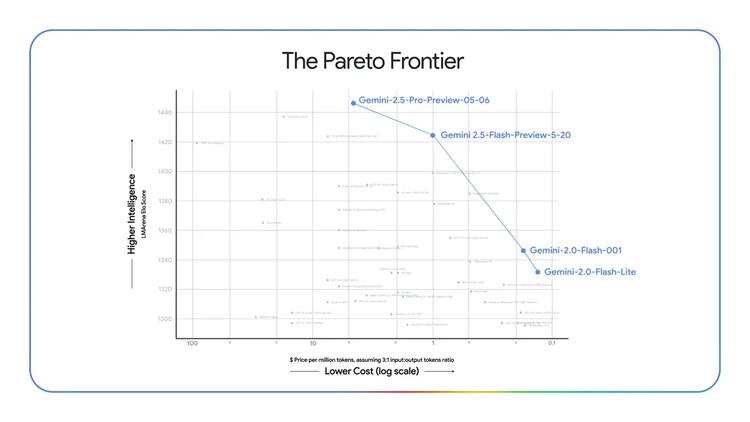
Google 公布了一系列 Gemini 2.5 系列的升级:其中轻量级的 Gemini 2.5 Flash 以速度快、成本低广受开发者欢迎,如今全新版本在推理、多模态理解、编程能力和长文本处理等多个方面全面升级,性能在 LMArena 榜单上仅次于旗舰版 2.5 Pro。作为轻量级模型,它在内部测试中还能节省 20 – 30% 的 token 使用量。
而对于更强的 2.5 Pro,谷歌也带来了一个全新的 " 深度思考模式 "(Deep Think),专门用来处理数学、编程这类复杂问题。它融合了最新的 AI 推理研究成果,包括并行思维技术,能在面对复杂问题时更像人一样 " 多角度思考 ",给出更周到、更靠谱的答案。目前只开放给少数用户测试。Gemini2.5 Pro 还通过集成 LearnLM,强化了在学习和教育场景的应用能力 。
此外,一个比较新的功能是,谷歌正在为 Gemini 2.5 Pro 和 2.5 Flash 增添更自然对话体验的原生音频输出能力,而 Gemini 多模态可能接入的最新视频生成模型 Veo 3,在视频质量上继续突破,且首次具备了原生音频生成能力,用户可以一句话生成匹配音效、背景环境声乃至角色对话的视频内容,并在文本理解、物理效果模拟和口型同步方面表现优异 。
而在榜单方面,Gemini 2.5 Pro 和 Gemini 2.5 Flash Preview 版本分别占据了大模型竞技场评测榜单的前两名。
显然,Gemini 坚持死磕原生多模态的技术路线,以及利用 Google 老本行搜索能力来增强模型研究能力的产品路线,含金量还在增加。
对于 Google 来说,Gemini 的模型能力 + 以 Gemini app 为核心的全能的单一 AI 通用助手 +Gemini" 接管 " 的 Google 全家桶,就是它此刻的 AI 战略。
Hassabis 也对 Gemini App 提出了自己的终极想法:" 我最终极的目标是让 Gemini 成为一个全能的助手。"
而通往这个目标路上,最近的一个突破,是之前还只是展示阶段的 AI Agent 项目 Project Astra 开始正式进入现实世界。

" 这是通往 AGI 的一个关键节点。"Hassabis 说。" 现在它的音频能力,记忆能力都得到了提升。"
Project Astra 以 Gemini Live 的新身份开始进入 Gemini App。在现场,他展示了一个修理自行车的案例:
用户呼唤出 Gemini,让她帮忙上网找到 Huffy 山地车的用户手册,并根据指令翻到刹车相关的特定页面;接着从 YouTube 上筛选出修复滑丝螺丝的教学视频,直接播放给你看。更厉害的是,Gemini Live 甚至能翻阅你过去的邮件,从你和自行车店的聊天记录里找出那个让人头疼的六角螺母的准确尺寸,并在墙上工具箱里高亮出对应的型号。
当发现还需要一个备用张力螺丝时,Gemini Live 迅速遵照指令,给最近的自行车店打电话问有没有货。
演示中还有一个重要细节,当用户的一位朋友闪现在门口,喊他去吃午饭时,Gemini 自动停止了说话,而等对方离开后,在用户提醒下,继续无缝衔接地汇报了自行车店的回电内容。
(插入修车视频)
这些技术的最终趋势,是让 Gemini 变得更加主动。
在硅星人参加的一个小型沟通会上,Hassabis 提到他对 AI 助手必须更加主动的看法。
" 如果你看看今天的工具,我会说它们大多是被动反应式的。也就是说,你通过查询或问题来输入,然后它做出回应。所以是你把所有的信息都投入到系统中。我们希望下一代和我们的 AI 助手能够做到的是,让它们具有预测性,能够提前提供帮助。例如,如果你要进行长途飞行,它可能会为你推荐一本适合在飞机上阅读的好书。或者,如果你有某种健身目标,它可能会主动提醒你今天要去跑步,或者建议你做一些与你长期目标相关的事情。所以我们认为,当这些主动型系统和代理系统能够预测你想要做什么时,它们的感觉会非常不同。"
Gemini app 当天也宣布了大量更新。
包括 Gemini live 功能的全面开放,它能更加实时,而且此前的小范围测试数据已经显示,人们比用打字会有 5 倍长的交互时间。同时,随着 Project Astra 变成成熟产品,摄像头实时互动和屏幕读取的能力也在 Gemini 里免费开放。
Gemini 里的 Deep Research 模式接下来允许以用户自己上传资料,之后更是可以在 Google 全家桶里打通使用你的各种数据库。此外 Canvas 更新了更强的编程模式,最新的图像模型 Imagen 4 也接入 Gemini。
而除了 Gemini 自己的 app 上的更多功能,Google 能让 Hassabis 实现 " 统一的主动 Agent" 这个想法,更关键因为 Google 有它积攒了多年的强大的搜索 + 全家桶。而且,Hassabis 已经为自己赢得了用 Gemini 更深入 " 接管 " 这些全家桶的权力。

与 Project Astra 从实验室走向 Gemini 相似,此前 Google 的 Project Mariner 也变成了 Gemini 里的 Agent mode。
" 我们认为智能体(agents)是结合了高级 AI 模型智能和工具访问权限的系统,因此它们可以在您的控制下代表您执行操作 。"Pichai 说。Google 引入了一种名为 " 教学与重复 " 的方法,即只需向它展示一次任务,它就能学习未来类似任务的计划 。
"Agent mode 可以同时完成多达十种不同的任务。这些智能体可以帮助您查找信息、进行预订、购买商品、做研究等等——所有这些都可以同时进行。"Hassabis 说。" 而且我们还会把它推广到更多产品,首先从浏览器开始。"
当天 Google 宣布,Chrome 将接入 Gemini 并拥有类似诸多通用 Agent 产品展示的功能,它能直接在你的浏览器页面中开始工作,帮你自动完成你指定的目标任务。
Google 通过 API 提供 Agent Mode 的能力,同时有它建立的开放的 Agent2Agent 协议,能让智能体之间相互通信,当天 Google 还宣布,它的 Gemini API 和 SDK 将兼容目前最流行的 Agent 与工具之间的协议 MCP 。
一切都集齐了。那些基于 Google 的 API 做出来的 AI 浏览器、需要不停调用浏览器的通用 Agent 产品们,可能要想想自己如何和 Google 的亲儿子 Chrome 这样的产品竞争了。
而 Google 接下来的计划是,它的全家桶都会在拥有了 Computer use 和 Astra 这样的 Agent 能力后的 Gemini 加持下,瞬间变成一个通用 Agent。
在 Google 的理解,Agent 可能根本就不是一个单独产品,而是任何 AI 产品的基础功能。

搜索彻底 Gemini 化
Google 在 OpenAI 最初的冲击中,一度让人感觉英雄迟暮,而外界关注它能否转身成功的关键之一就是它是否能对自己躺着赚钱的基础——搜索业务动刀。
而现在看来,它的动作还是很快的。
" 仅仅是一年时间,人们用搜索的方式已经深刻地改变了。"Google 搜索负责人 Elizabeth Reid 说。" 人们开始问更长的问题。因此我们把 Gemini 和搜索对世界信息的理解合并到一起。"
当天全美的 Google 用户会看到 Google 多年来又一次大的改变,在首页的第一个 tab 的位置,变成了 AI Mode。相比于小规模试验性质的 AI Overview,这是又一个大的自我革新的动作。
AI Mode 的一个最大变化,其实是 Gemini 的 AI 能力和 Google 搜索的技术的更深入的融合,Google 称在底层技术上,它使用查询扇出 ( query fan-out ) 技术,它会将问题分解为子主题,并同时替用户自动发出多个查询。这使得 AI Mode 能够比传统的 Google 搜索更深入地探索网络,帮助用户发现网络上更多的内容,找到更好的答案。此外,deep search 模式也加入到 AI Mode 的选项里,可以在搜索里也制作深度的报告。
" 这就是 Google 搜索的未来。从信息到智能。"Elizabeth Reid 说。
Gemini 对搜索核心业务的 " 接管 ",也让 Google 此前一直想做但有所停滞的一些业务可以有新的做法。比如电商。
Google shopping 基本也是建立在搜索入口流量之上的业务,此前也不温不火,而此次基于 Gemini 的改造,它有了一个全新的交互。
在 I/O 现场,Shopping 得到了少有的 live demo 机会。Google 展示了一个虚拟试衣(Virtual Try-on)功能。现场掀起了一阵小高潮。

以往我们线上购物时,只能看着模特图脑补自己穿上身的样子,生怕买了不合适。如今,只需上传一张自己的全身生活照,Google 专门训练过的更了解人们身形和衣服褶皱的模型,会通过先进的身体映射和服装形变技术,将商品 " 穿 " 在你的数字分身上,褶皱、垂坠感都无比逼真,让人隔着屏幕也能清楚判断上身效果。
挑中款式和尺码后,还可以设置期望价格,让 Chrome 的 AI Agent 去盯着价格,当低价出现后,agent 自动下单,把支付界面推送给你由你最后操作支付。
Google 把所有最重要的入口位置都给了 Gemini,当然也希望它能激活 Google 已有的各种业务。
Flow 和一堆彩蛋
Gemini 系列模型在多模态上的疯狂进展,最直接惠及的就是创作者。
Google 此次也更新了图像模型 Imagen 4,和视频模型 Veo 3。
Imagen 4 作为 Google 最先进的文生图模型,不仅图像质量大幅提升,在文字和排版的准确性与创意性上也令人惊艳。例如让它设计一张以 Chrome 小恐龙为主角的音乐节海报,Imagen 4 不仅准确无误地把文字 " 印 " 了上去,还巧妙地将恐龙骨骼元素融入字体设计,堪称神来之笔。
视频生成模型 Veo 3 则更进一步,懂物理规律、生成电影级的视频画面之外,还能同步创作出自然语音对话和逼真的环境音效 。在制作一位饱经沧桑的男子独自在波涛汹涌的大海上航行的视频时,Veo 3 除了完美渲染海浪动态、人物面部细微的情感变化,还为他配上了一段富有磁性的内心独白,意境十足。另一段森林中老猫头鹰和小獾的对话视频,更是活灵活现。
(视频案例)
这些能力让 Google 特意单独又推出了一个 app —— Flow。它可以让普通人也能轻松创作出专业级视频 。

它融合了 Google 最顶尖的 AI 技术——视频生成模型 Veo、图像生成模型 Imagen 以及强大的 Gemini 智能,在发布会当天已正式上线。
它的操作追求尽可能简单,用户可以上传自己的图片,或用 Flow 内置的 Imagen 模型,通过文字描述直接生成新元素 。然后像导演一样只需动口,用简单的提示词就能组装这些生成的图像片段,详细描述镜头和摄像机指令(如推拉摇移)后, Flow 会像个经验丰富的副导演,迅速搞定一切,并在 " 场景构建器 " 中呈现,供你随时调整 。用户也可以通过点击 "+" 号,告诉 Flow 新剧情,不停的制作下去。如果某个镜头不尽如人意,Flow 也提供了传统编辑工具,让你轻松修剪。最后还能导出到主流编辑软件做更多处理。
(flow 的视频)
当然,这些背后是燃烧的 token。
Google 也在 Flow 的展示后,公布了新的套餐定价。
它将原本的 AI Premium 订阅正式更名为 " 谷歌 AI Pro",并推出了全新的高端版 " 谷歌 AI Ultra",月费高达 249.99 美元。Pro 版月费仍为 19.99 美元。
Ultra 版,可以看作是谷歌 AI 的 " 全家桶 VIP 套餐 ":除了拥有 Pro 的全部功能外,还提供 30TB 云端存储、YouTube Premium,以及 Veo 3)、NotebookLM 最强模型版本和 Gemini 的增强体验。同时用户还可抢先体验 Deep Think 模式、实验版 Agent Mode,以及基于 Project Mariner 的智能体功能。Ultra 今日起在美国开放订阅,并将很快拓展至更多国家。

而就像一部大片一样,Google I/O 也有诸多彩蛋,它并不是放在结尾,而是藏在了密集的发布之中。
一个有意思的一带而过的彩蛋,是 Gemini 的 Diffusion 模型,它不是用在图片上,而是用在文本生成上。这让它的生成速度快的惊人。在现场的展示上,输入完成后,它几乎是瞬间完成了输出。
" 传统的自回归语言模型一次生成一个词或者 token。这种序列化的过程可能会很慢,并且会限制输出的质量和连贯性。扩散模型的工作方式则不同。它们并非直接预测文本,而是通过逐步优化噪声来学习生成输出。这意味着它们可以非常快速地对一个解决方案进行迭代,并在生成过程中纠正错误。这使得它们在编辑等任务中表现出色,包括在数学和代码相关的场景下。" Gemini 团队介绍。
而除了速度,这种尝试也在暗示着 Gemini 在模态融合之外,对模态生成和多模态推理融合的潜在的发力方向。
你现在可以在网站上加入 waitlist 来试用这个模型。

这是一场信息量巨大的 Google I/O,Google 正在回到自己的节奏,这些强大的更新,和更清晰的思路,让人感觉可能 AI 最终真的是所有人努力半天,Google 拿走胜利的游戏。
