{kind=link}
2025年中国多模态大模型行业模型现状 图像、视频、音频、3D模型等终将打通和融合
行业主要上市公司:阿里巴巴 ( 09988.HK,BABA.US ) ; 百度 ( 09888.HK,BIDU.US ) ; 腾讯 ( 00700.HK, TCEHY ) ;科大讯飞 ( 002230.SZ ) ;万兴科技 ( 300624.SZ ) ;三六零 ( 601360.SH ) ;昆仑万维 ( 300418.SZ ) ; 云从科技 ( 688327.SH ) ;拓尔思 ( 300229.SZ ) 等
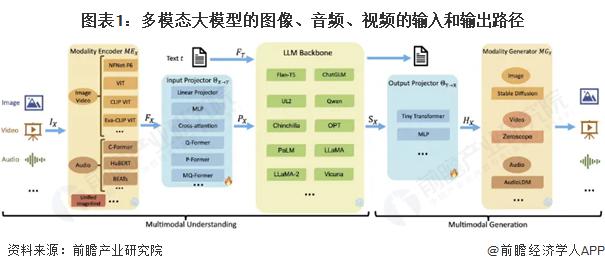
多模态大模型的模型路径
多模态大模型的探索正在逐步取得进展,近年来产业聚焦在视觉等重点模态领域突破。理想中的 "Any-to-Any" 大模型,Google Gemini、Codi-2 等均是处于探索阶段的方案,其最终技术方案的成熟还需要在各个模态领域的路线跑通,实现多模态知识学习,跨模态信息对齐共享,进而实现理想中多模态大模型。现阶段产业主要的工作还是聚焦在视觉等典型的重点模态,试图将 Transformer 大模型架构进一步在图像、视频、3D 模型等模态领域引入使用,完善各个模态领域的感知和生成模型,再进一步实现更多模态之间的跨模态打通和融合。
多模态大模型的图像模型
早在 2023 年 LLM 的流行之前,过去产业界在对于图像的理解和生成模型领域已经打下了坚实的基础,其中也产生了 CLIP、Stable Diffusion、GAN 等典型的模型成果,孕育出了 Midjourney、DALL · E 等成熟的文生图应用。而更进一步,产业界也在积极探索将 Transformer 大模型引入图像相关任务领域 ( ViT,Vision Transformer;DiT,Diffusion Transformer ) ,探索统一视觉大模型的建立,以及将 LLM 大语言模型与视觉模型进行更加密切的融合,包括近年来的 GLIP、SAM、GPT-V 都是其中的重点成果。
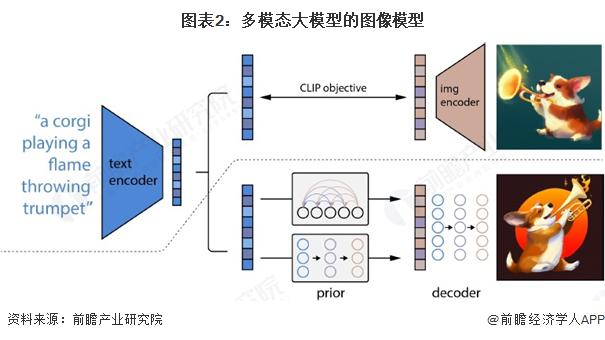
注:利用真实文本描述,通过 CLIP 生成的图像特征
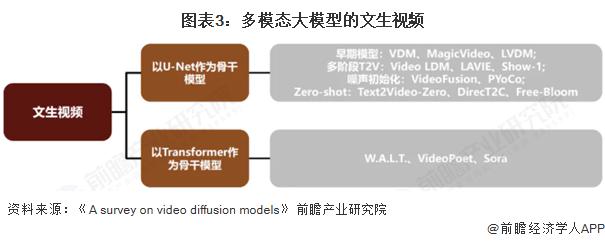
多模态大模型的视频模型
由于视频本质上是由很多帧的图像叠加而成,因此本质上语言与视频模态的融合和语言和图像具有相当多的互通之处,产业界也在尝试将图像生成模型迁移到视频生成,先基于图像数据进行训练,再结合时间维度上的对齐,最终实现文生视频的效果。其中近年来也产生了 VideoLDM、W.A.L.T. 等典型的成果,并在近期也出现了 Sora 这样具有明显突破性效果的模型,其在视频生成领域沿用了 Diffusion Transformer 架构,并在视频类场景首次呈现出 " 智能涌现 " 的迹象。
视频本质上是一系列图像的连续展示,图片生成是视频生成的基础。图片生成的主流技术即扩散模型同样也是视频生成的主流技术,目前主流的文生视频模型的技术路线为基于文生图模型,通过在时间维度加入卷积或注意力,在生成的关键帧基础上实现时序对齐得到视频。在此基础上,插帧 + 超分、初始噪声对齐、基于 LLM 增强描述等方法均有助于增强时序对齐能力,实现更高质量的视频生成。Zero-shot 领域的一系列研究则能够实现无需训练,直接将图片生成模型转化为视频生成模型。
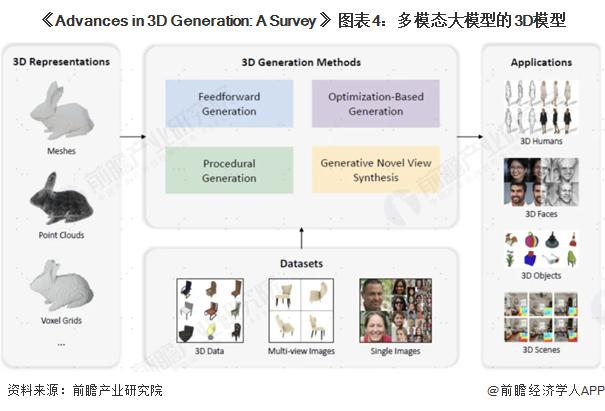
多模态大模型的 3D 模型
实际上 3D 是由 2D+ 空间信息构成,因此类似于由图像生成到视频生成的延伸,2D 图片的生成方法理论上也可以迁移到 3D 中。近年来产业界也在积极探索将图像领域的 GAN、自回归、Diffusion、VAE 等骨干模型在 3D 模型生成任务中的扩展,其中也产生了 3D GAN、MeshDiffusion、Instant3D 等重点的模型成果。但相比图像和视频生成,目前的 3D 模型生成技术还处于早期发展阶段,相关模型的成熟度仍有较大提升空间。
3D 数据表征:包括网格 ( Mesh ) 、点云 ( Point clouds ) 等显式表示,以及 NeRF ( Neural radiance fields,神经辐射场 ) 等隐式表示,还包括体素 ( Voxel grids,3D 空间中的像素 ) 这类混合表示,其中 NeRF 具有强大的三维表达能力和潜在的广泛应用范围,是 3D 数据表征的关键技术 ;
3D 数据集:包括 3D 数据 ( 数据量和精度有限 ) 、多视角图片 ( 用途最为广泛 ) 、单张图片 ( 使用仍具有较大难度 ) 等。目前 3D 对象数据集仍然稀缺,代表性的数据集包括 ShapeNet ( Chang 等,2015 ) 构建了 5.1 万个 3D CAD 模型,为 3D 数据集的充实做出开创贡献 ;Deitke 等 ( 2023 ) 构建了 Objaverse 和 Objaverse-xl 数据集,分别有 80 万和 1000 万个 3D 对象 ;
3D 生成模型:前馈生成 ( 通过前向传递中直接生成结果 ) 、基于优化的生成 ( 每次生成需要迭代优化 ) 、程序生成 ( 根据规则创建 3D 模型 ) 、生成式新视图合成 ( 生成多视角图像 ) ;
3D 应用:包括 3D 人生成、3D 人脸生成、3D 物体生成、3D 场景生成等应用。
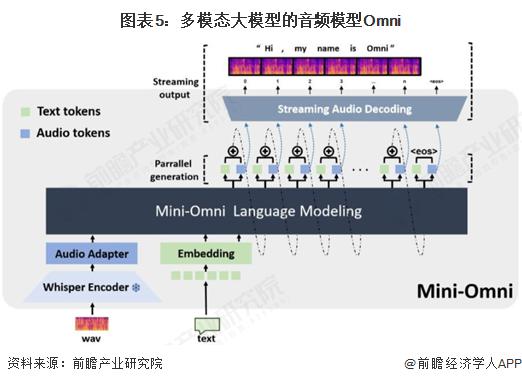
多模态大模型的音频模型
语音相关的 AI 技术在过去多年中已经较为成熟,但近年来 Transformer 大模型在 AI 音频领域的投入应用,还是成功推动了相关技术再上台阶,实现更优的音频理解和生成效果,其中重点的项目成果包括 Whisper large-v3、VALL-E 等。语音技术沿革可分为三阶段,深度学习驱动发展加速。语音技术主要向增强泛化能力的方向持续延伸,Transformer 架构引领语音技术迭代浪潮。泛化能力是指模型对于未经训练的数据的适应能力,技术基础来自具有强大学习能力的网络架构和大量多样化的数据训练。语音模型泛化能力的增强主要体现在:从覆盖单一语种到多语种和方言,从处理人声到自然声音、音乐,从简单语音识别或合成到零样本学习和多任务集成。
Omni 模型是利用 neural audio codec,主要是对音频进行编码以实现音频合成。文本和声波会先分别进入 embedding 和 adapter 进行编码,再通过 Omni 模型进行合成和预测音频的 token,最后通过扩散模型进行训练,量化再用解码器合成音频。
更多本行业研究分析详见前瞻产业研究院《全球及中国多模态大模型行业发展前景与投资战略规划分析报告》
同时前瞻产业研究院还提供产业新赛道研究、投资可行性研究、产业规划、园区规划、产业招商、产业图谱、产业大数据、智慧招商系统、行业地位证明、IPO 咨询 / 募投可研、专精特新小巨人申报、十五五规划等解决方案。如需转载引用本篇文章内容,请注明资料来源(前瞻产业研究院)。
更多深度行业分析尽在【前瞻经济学人 APP】,还可以与 500+ 经济学家 / 资深行业研究员交流互动。更多企业数据、企业资讯、企业发展情况尽在【企查猫 APP】,性价比最高功能最全的企业查询平台。